Development of DL Acceleration Framework for Reconfigurable Datacenter
Summary
Our research project aims to create an advanced DL acceleration framework tailored for datacenters, focusing on optimizing AI workload management and computational resource efficiency. We seek to develop various scheduling algorithms for enhancing the processing performance, scalability, and cost-effectiveness of AI applications.
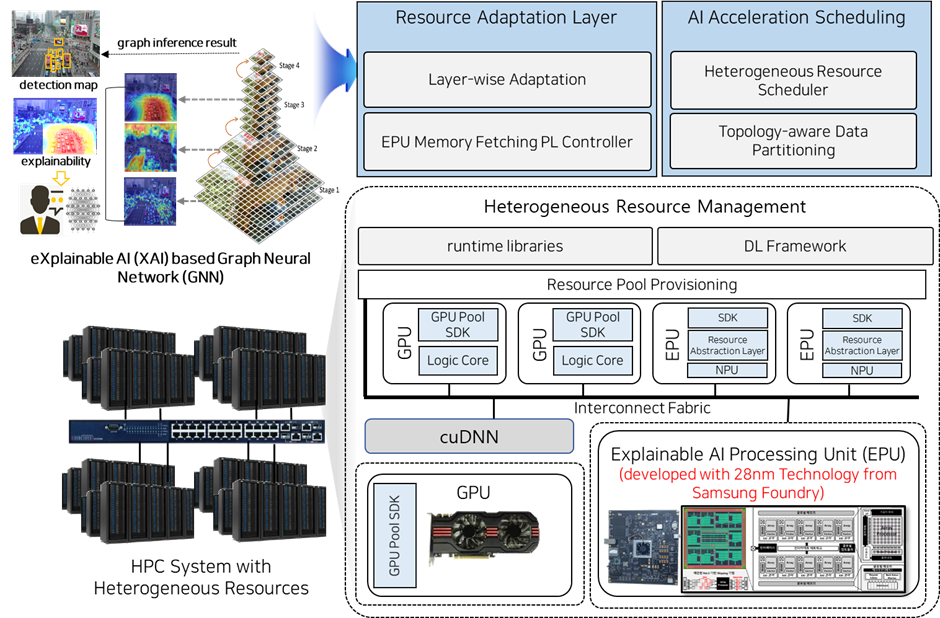
As the demand for artificial intelligence (AI) continues to grow, datacenters are faced with the challenge of efficiently managing and accelerating AI workloads. Our research project addresses this challenge by developing a DL acceleration framework designed for heterogeneous datacenters. This framework aims to enhance the utilization of computational resources, the performance of AI models, and reduce operational costs.
- Resource Adaptation for Adapting AI Model in GPUs and ASICs: A cornerstone of our project is the development of adaptive resource management techniques that enable AI models to seamlessly operate across a variety of hardware platforms, including different GPUs and application-specific integrated circuits (ASICs). Especially, we design explainable AI processing unit (EPU) cooperating with Samsung Foundry during this project.
- Heterogeneous Resource Scheduler for AI Training/Inference Workload: We are developing a heterogeneous resource scheduler which intelligently allocates computational resources for multi-tenant AI training and inference tasks by considering the unique requirements and priorities of each workload. By doing so, it maximizes resource utilization and minimizes processing time and operational costs, enabling datacenters to handle larger volumes of AI workloads.
- Interconnection Topology-aware Workload Assignment: This approach optimizes the distribution of AI workloads across the datacenter’s computational resources by considering the physical and logical interconnections between them. This ensures that data transmission times are minimized, and computational loads are balanced, leading to improved overall performance and reduced latency.